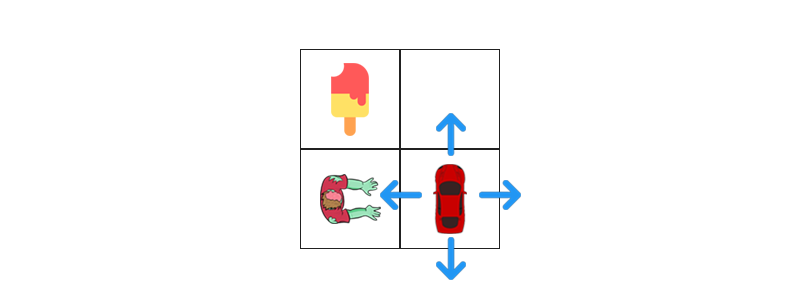
1.) Mapping Agent(car) coordinates/situation into states
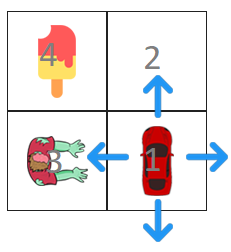
x2-y2 is state 1 x2-y1 is state 2 x1-y2 is state 3 x1-y1 is state 4
2.) Adding random scenarios as inputs
Syntax: state action reward next-state
Results: (Note: Press compute policy button multiple times until it gets the optimal policy)
Per Action:
Congratulations! found optimal solution from every state
A more complicated example